高级SQL
函数
内置函数
字符串函数
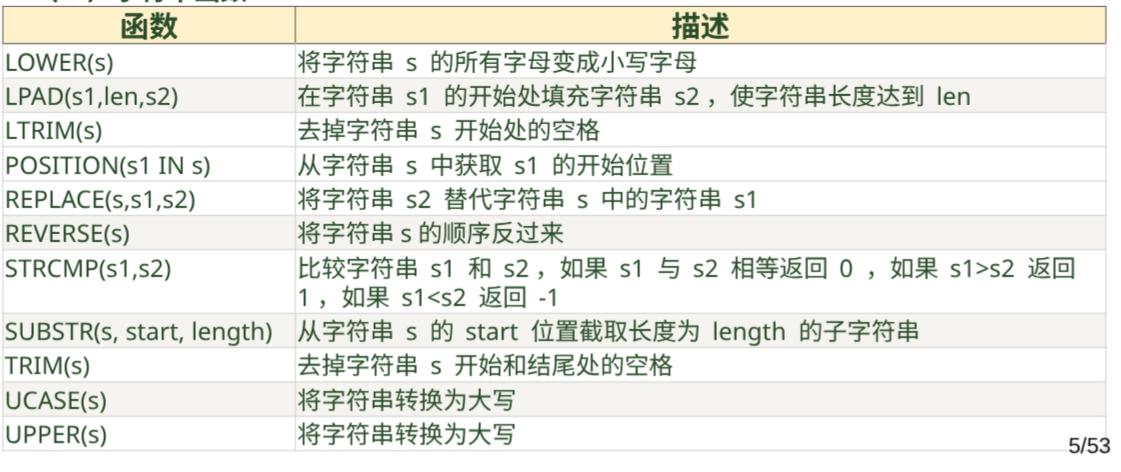
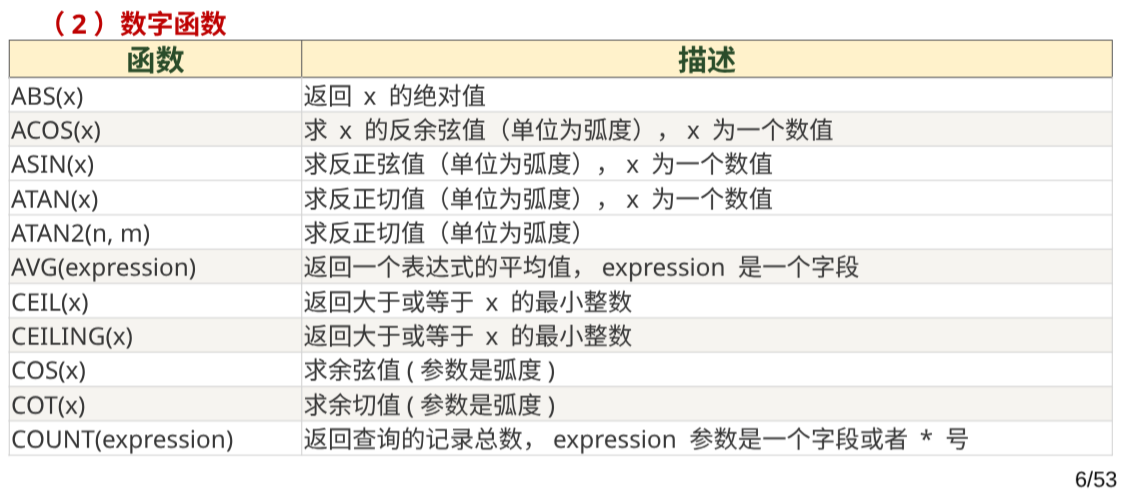
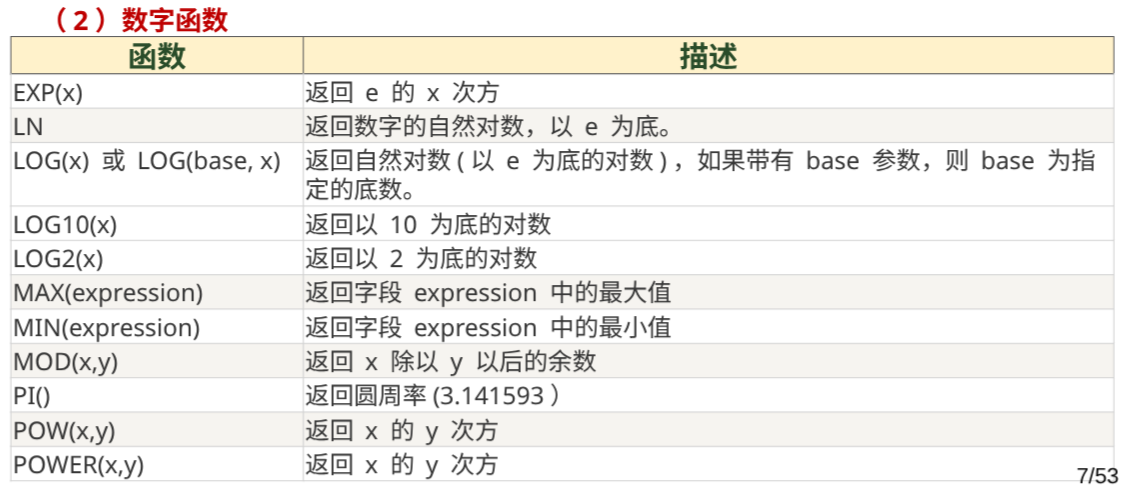
数字函数
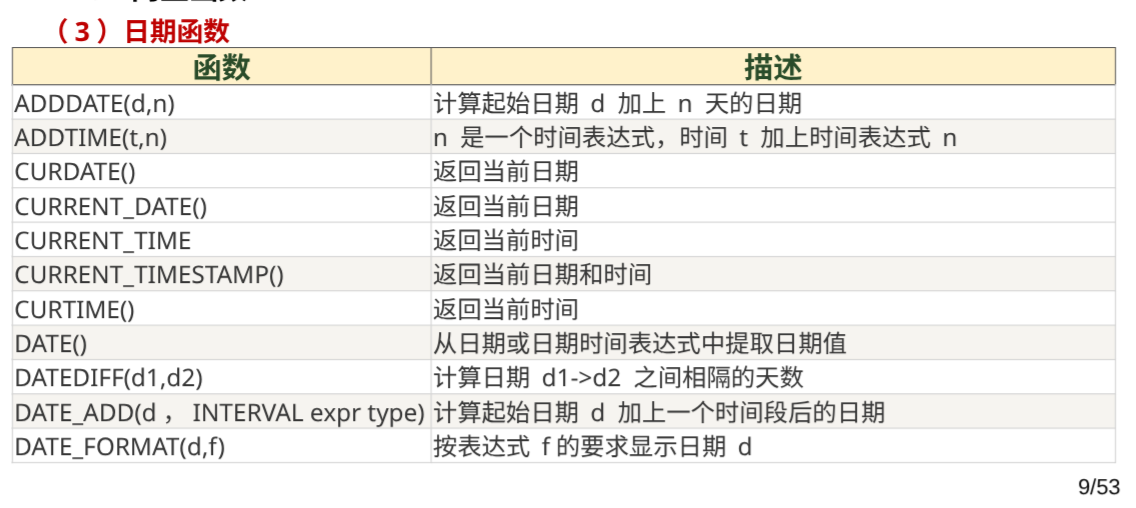
日期函数
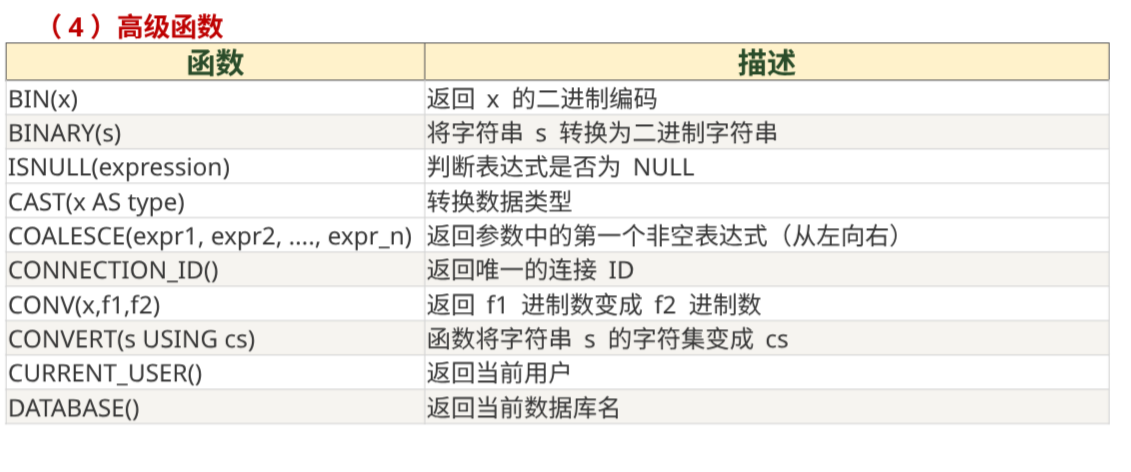
高级函数
自定义函数
创建函数
sql
CREATE [OR REPLACE] FUNCTION function_name [(parameters)]
RETURNS return_data_type {IS|AS} [local_declarations]
BEGIN
executable_statements
[EXCEPTION exception_handler]
END [function_name];eg:
sql
delimiter $$
CREATE OR REPLACE FUNCTION get_employee_name (p_employee_id IN NUMBER)
RETURN VARCHAR2
IS
v_employee_name VARCHAR2(100);
BEGIN
SELECT employee_name
INTO v_employee_name
FROM employees
WHERE employee_id = p_employee_id;
RETURN v_employee_name;
EXCEPTION
WHEN NO_DATA_FOUND THEN
RETURN NULL;
END get_employee_name$$delimiter用来更改语句结束符, 默认是分号, 在定义函数或存储过程时, 通常会使用其他符号(如$$)来避免与函数体内的分号冲突.
调用函数
sql
SELECT function_name(arguments);存储过程
存储过程就是存储在数据库当中的可以执行特定工作(查询/更新)的一组SQL代码的程序段.
与自定义函数区别
- 自定义函数有且仅有一个返回值, 可以直接在表达式中嵌入调用. 存储过程可以没有返回值, 也可以有任意个输出参数, 必须单独调用.
- 执行的本质都一样
- 函数可以嵌入在SQL使用, 存储过程不可以
- 函数限制较多, 如不能用临时表, 只能用表变量
- 一般情况下存储过程实现的功能更复杂, 函数的实现的功能针对性更强
- 存储过程可以返回参数, 函数只能返回值或者表对象
优点
- 只在创造时进行编译, 之后再次执行不需要编译, 提供执行速度
一般SQL语句每执行一次就编译一次.
- 封装复杂操作, 提高开发效率
- 提高安全性, 可以通过权限控制用户对数据的访问
- 可复用
创建存储过程
sql
CREATE PROCEDURE procedure_name [(in|out|inout) 参数 数据类型, ...]
BEGIN
SQL语句;
END;MySQL如果不显示指定in/out/inout, 默认是in类型.
- IN 默认类型, 值必须在调用时指定, 值不能返回
- OUT 值可以返回
- INOUT 既可以传入值, 也可以返回值
调用MySQL存储过程时, 需要在过程名字后面加(), 即使没有参数
CALL procedure_name();
eg:
sql
DROP PROCEDURE IF EXISTS test;
DELIMITER $$
CREATE PROCEDURE test (IN emp_id INT, OUT emp_name VARCHAR(100))
BEGIN
SELECT employee_name INTO emp_name
FROM employees
WHERE employee_id = emp_id;
END$$
DELIMITER ;
CALL test(1, @name);变量
- 定义
sql
DECLARE var_name data_type [DEFAULT value];- 赋值
sql
SET var_name = value;
-- or
SELECT column_name INTO var_name FROM table_name WHERE condition;控制结构
- 条件语句
sql
IF condition THEN
statements;
[ELSEIF condition THEN
statements;]
[ELSE
statements;]
END IF;- CASE语句
sql
CASE expression
WHEN value1 THEN
statements;
WHEN value2 THEN
statements;
[ELSE
statements;]
END CASE;- 循环语句
while
sql
WHILE condition DO
statements;
END WHILE;loop
sql
lable:LOOP
statements;
LEAVE label; -- 退出循环, break
ITERATE label; -- 继续下一次循环, continue
END LOOP;repeat
sql
REPEAT
statements;
UNTIL condition
END REPEAT;触发器
在对指定表执行INSERT/UPDATE/DELETE操作时, 自动执行的存储过程.
作用: 实现由主键和外键所不能保证的复杂的参照完整性和数据的一致性.
触发器是一种高级约束, 可以定义比用CHECK约束更为复杂的约束.
- 可执行复杂的SQL语句
- 可引用其它表的列
- 所有数据值均正确的状态
与存储过程区别
- 触发器不能被显式调用, 存储过程可以
分类
- DDL触发器: 在数据库对象(表, 视图, 存储过程等)上执行CREATE, ALTER, DROP等操作时触发
- DML触发器: 在对表执行INSERT, UPDATE, DELETE等操作时触发
创建触发器
- DDL
sql
CREATE [OR REPLACE] TRIGGER trigger_name
{BEFORE|AFTER} {CREATE|ALTER|DROP}
ON database
BEGIN
SQL语句;
END;- DML
sql
CREATE [OR REPLACE] TRIGGER trigger_name {BEFORE|AFTER|INSTEAD OF} {INSERT|UPDATE|DELETE}
ON 表名
[FOR EACH ROW]
BEGIN
SQL语句;
END;- FOR EACH ROW表示触发器是行级触发器, 否则是语句级触发器.
每一行都执行一次, 否则只对整个表执行一次
- Old: 代表被修改或删除的记录
- New: 代表新插入或修改后的记录
eg:
sql
DELIMITER $$
CREATE TRIGGER before_employee_insert
BEFORE INSERT ON employees
FOR EACH ROW
BEGIN
IF NEW.salary < 0 THEN
SET NEW.salary = 0;
END IF;
END$$
DELIMITER ;嵌套触发器
当一个触发器执行的操作引发另一个触发器时, 就会发生嵌套触发器.
禁用嵌套
sql
EXEC sp_configure 'nested triggers', 0;启用嵌套
sql
EXEC sp_configure 'nested triggers', 1;触发器执行原理
触发器触发时, 创建DELETED表和INSERTED表, 只读, 触发器执行后删除.
- DELETED表: 存放执行DELETE或UPDATE操作前的行. 数据库在执行这些语句前, 会自动将被删除/更新前的行保存到DELETED表中.
- INSERTED表: 存放执行INSERT或UPDATE操作后的行. 数据库在执行这些语句后, 会自动将新插入/更新后的行保存到INSERTED表中.
管理触发器

不能在触发器使用的语句
