语法制导的翻译
语法制导
语法分析基于CFG上下文无关文法, 只考虑某一句的正确.
Syntax-Directed Definition(SDD)是上下文无关文法和属性/规则的结合
- 属性和文法符号相关联, 按照需要来确定各个文法符号需要哪些属性
- 规则和产生式相关联
SDD三要素: 文法, 属性, 规则
属性可视为语义的具象化表示: 类型, 值, 名字, 地址...
对于文法大符号X和属性a, 用X.a表示分析树中某个标号为X的结点的值.
- 一个分析树结点和它的分支对应一个产生式规则, 而对应的语义规则确定了这些结点上属性的取值和计算
eg1

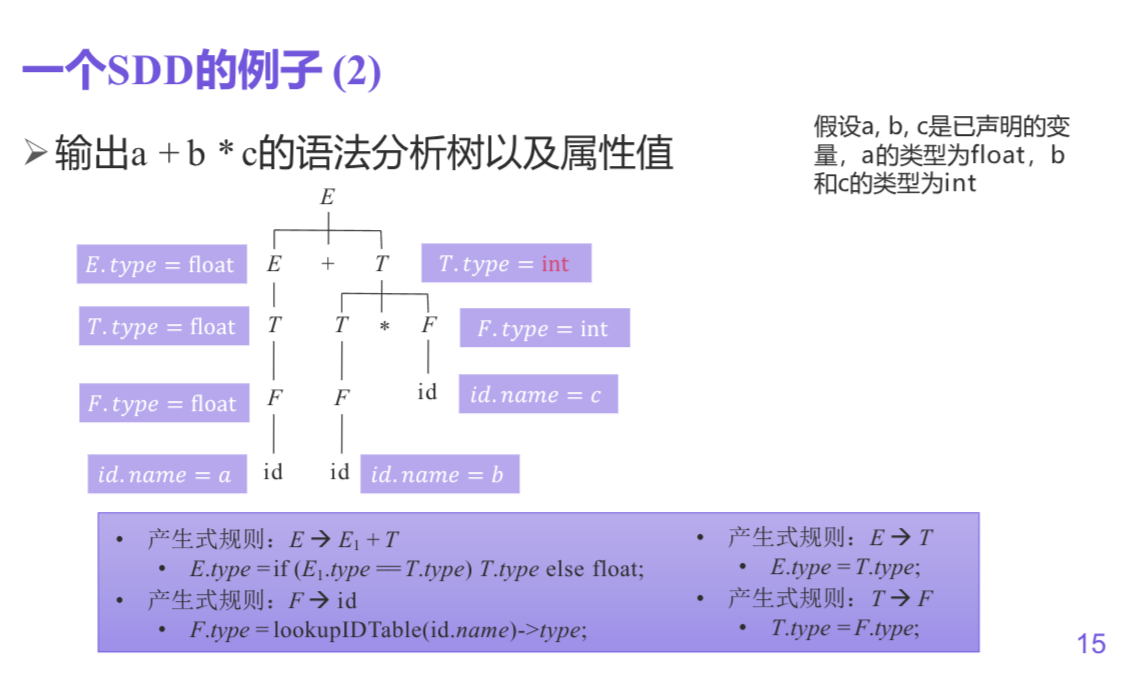
综合属性和继承属性
- 综合属性
- 结点N的属性值由N的产生式所关联的语义规则来定义
- 通过N的子结点或N本身的属性值来定义
- 继承属性
- 结点N的属性值由N的父结点所关联的语义规则来定义
- 依赖于N的父结点, N本身和N的兄弟结点上的属性值
约束:
- 不允许N的继承属性通过N的子结点上的属性来定义, 但允许N的综合属性依赖于N本身的继承属性
- 终结符号有综合属性(来自词法分析), 但无继承属性

S属性的SDD
只包含综合属性的SDD
- 每个语义规则都根据产生式体中的属性值来计算头部非终结符号的属性值
S属性的SDD可以和LR语法分析器一起实现
归约时, 按照语义规则计算归约得到的符号的属性值
语义规则一般不应该有复杂的副作用
- 要求副作用不影响其他属性的求值
- 没有副作用的SDD称为属性文法
SDD的求值顺序
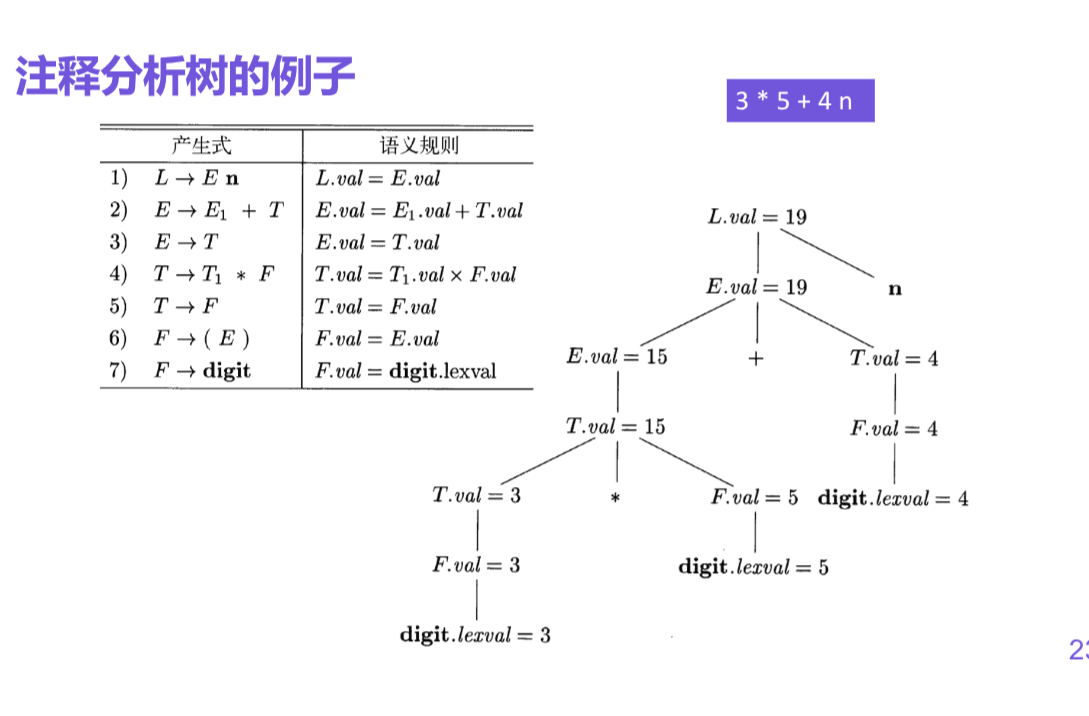
注释语法分析树
- 包含了各个结点的各属性值的语法分析树
步骤:
- 对于任意的输入串, 首先构造出相应的分析树
- 给各个结点(根据其文法符号)加上相应的属性
- 按照语义规则计算这些属性的值
如果某个结点N的属性a为f(N1.b1,N2.b2, ..., Nk.bk), 那么需要先算出N1.b1, N2.b2, ..., Nk.bk的值
如果可以给各个属性值排除计算顺序, 那么这个注释分析树就可以计算得到.
S属性的SDD一定可以按照自底向上的方式求值
可以用依赖图来表示计算顺序, 这些值的计算顺序形成一个偏序关系, 如果依赖图中出现了环, 表示属性值无法计算.
依赖图
描述了某棵特定的分析树上各个属性之间的信息流(计算顺序)
各个属性值需要按照依赖图的拓扑顺序计算
如果存在环, 无法计算.
特定类型的SDD一定不包含环, 且有固定的计算顺序, 如S属性的SDD和L属性的SDD
在分析树上计算SDD
按照后序遍历的顺序计算属性值即可
void postorder(N) {
for (从左边开始, 对N的每个子结点C) {
postorder(C);
}
对N的各个属性求值
}S属性SDD的局限
每个属性都是综合属性
无法计算同时需要继承和综合属性的语义信息
L属性的SDD
每个属性
- 是综合属性
- 或者是继承属性, 且A -> X1 X2 ... Xn中计算Xi.a的规则只用
- A的继承属性, 或者
- Xi左边的文法符号Xj的继承属性或综合属性(j<i)
- Xi自身的继承属性或综合属性
特点
- 依赖图的边
- 综合属性从下到上
- 继承属性从上到下, 或从左到右
- 计算一个属性值时, 它所依赖的属性值都已计算完毕
自顶向下语法分析
对于每个非终结符号A, 调用其对应过程前计算继承属性, 从过程返回前计算综合属性
在处理规则
- 在调用X_i()之前计算X_i的继承属性
- 在该产生式对应的代码的最后计算A的综合属性
- 如果所有文法符号的属性计算按上面的方式进行, 计算顺序必然和依赖关系一致
void L_dfvisit(n) {
for (m = 从左到右n的的每个子结点do) {
计算m的继承属性;
L_dfvisit(m);
}
计算n的综合属性;
}
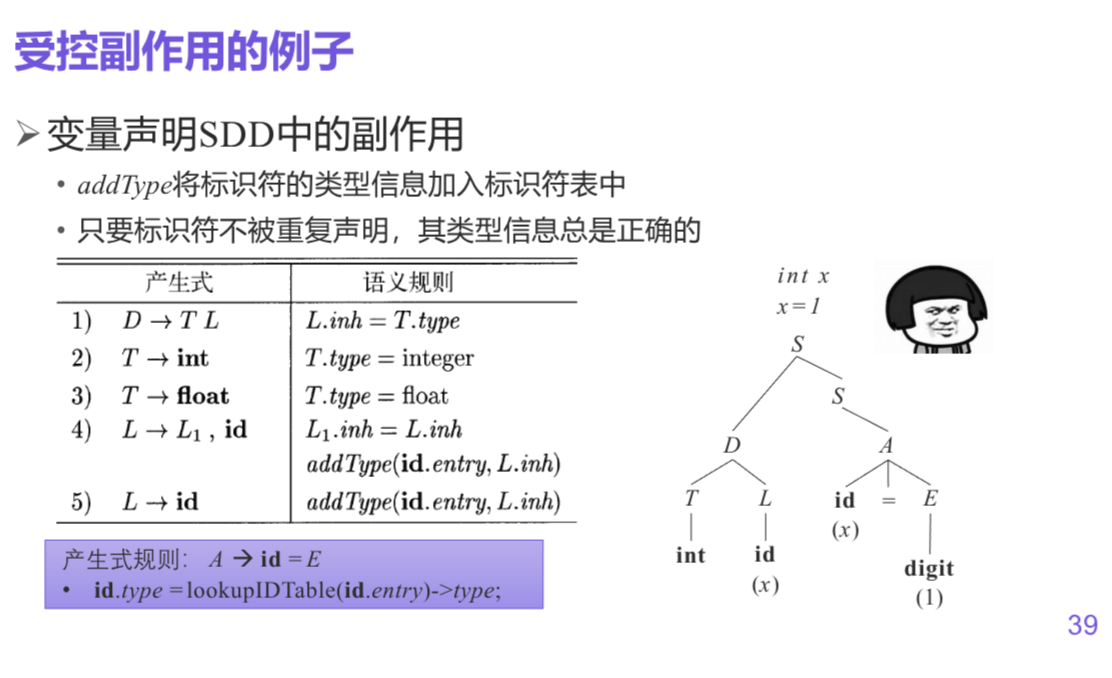
具有受控副作用的语义规则
属性文法没有副作用, 但增加了描述的复杂度
受控的副作用
- 不会对属性求值产生约束, 即可以按照任何拓扑顺序求值, 不会影响最终结果
- 或者对求值过程添加简单的约束
语法制导翻译的应用
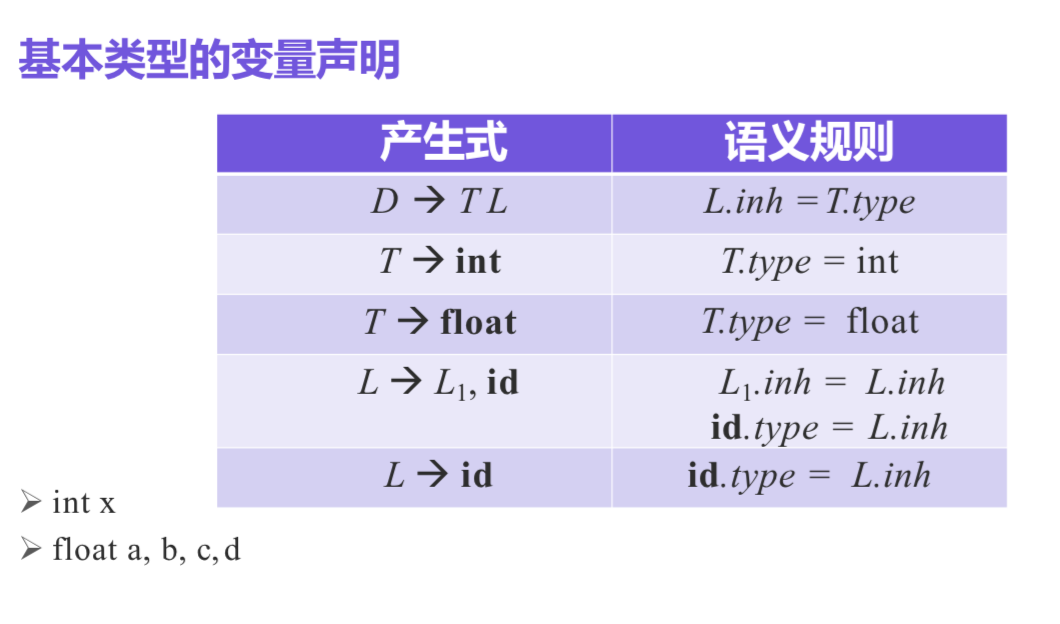
类型的结构
类型包括两个部分: T -> B C
- 基本类型B
- 分量C
分量形如[2][3], 表示2*3的二位数组, 如int[2][3]
数组构造算符array(n, t)
- n表示数组的大小
- t表示数组元素的类型
array(2, array(3, int))表示int[2][3]
抽象语法树的构造
语法分析树
- 具体语法树(Concrete Syntax Tree, CST)
- 保留所有词法元素
包含对分析无用的东西
- 所有词法元素都有对应结点
结点数量大
- 完整地还原非终结符到串的通道过程
包括所有中间推导过程, 引入大量中间节点
- 严格符合源语言的上下文无关文法
可根据文法自动生成
- 抽象语法树(Abstract Syntax Tree, AST)
- 只保留必要的词法元素
- 某些词法元素信息存入父节点的属性
- 移除没有实质信息的中间推导过程
- 不符合源语言的上下文无关文法
AST的优势:
- 更少的结点数量与种类
- 更易于分析和处理
- 独立于具体文法
抽象语法树
- 每个结点代表一个语法结构, 对应于运算符
- 结点的每个子结点代表其子结构, 对应于运算分量
- 表示这些子结构按照特定的方式组成了较大的结构
- 可以忽略掉一些标点符号等非本质的东西
表示方法:
- 每个结点用一个对象表示
- 对象有多个域
- 叶子结点只存放词法值
- 内部结点存放了op值和参数(通常指向其它结点)
语法制导的翻译方案
语法制导的翻译方法(SDT)是在产生式体中嵌入语义动作(程序片段)的上下文无关文法
基本实现方法:
- 建立语法分析树(CST)
- 将语义动作看作是虚拟结点(绑定语义动作)
- 深度优先, 从左到右地遍历分析树, 在访问虚拟结点时执行相应的语义动作
基本文法是LR的, SDD是S属性的
基本文法是LL的, SDD是L属性的
eg
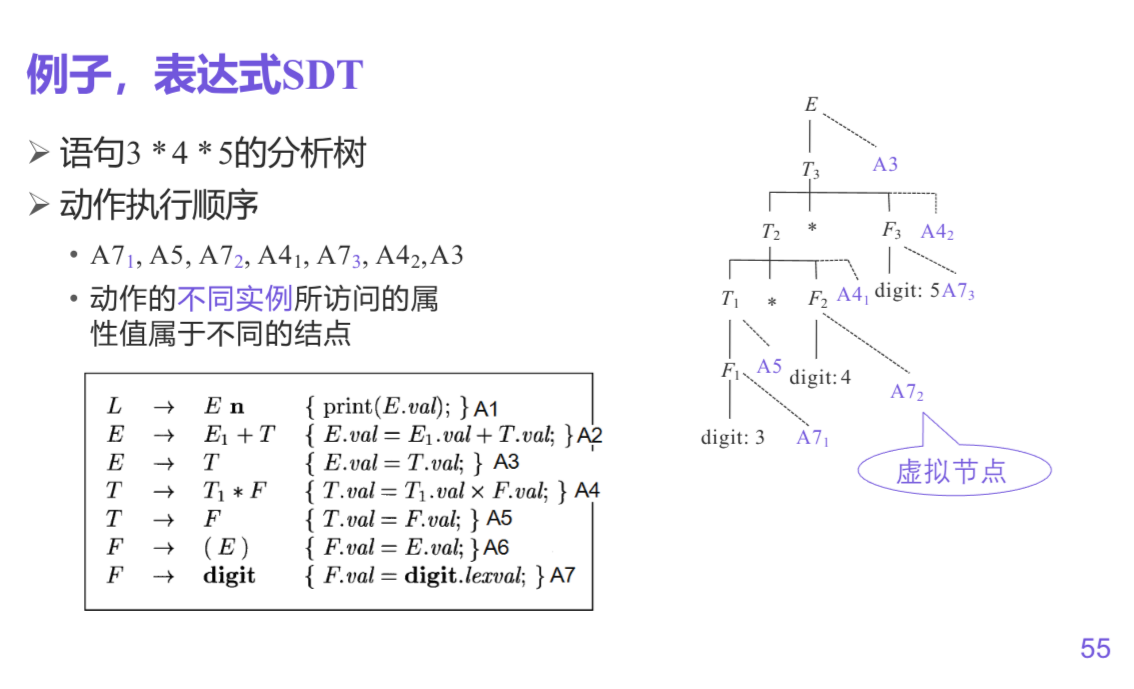
后缀翻译方案
文法可以自底向上分析的且其SDD是S属性的, 必然可以构造出后缀SDT
后缀SDT: 所有动作都在产生式最右端的SDT
构造方法
- 将每个语义规则看作是一个赋值语义动作
- 将所有的语义动作放在规则的最右端