SQL介绍
SQL语言分类
SQL: Structured Query Language (结构化查询语言)
- 数据定义语言DDL
- 数据定义语言DDL
- 事务控制语言TCL
- 数据控制语言DCL
- 数据操纵语言DML
- 数据操纵语言DML
- 数据查询语言DQL
数据定义语言DDL
SQL语言中集中负责数据结构定义与数据库对象定义的语言
create, drop, alter
事务控制语言TCL
用于管理数据库中的事务, 管理由DML语句所做的更改.
commit, rollback
数据控制语言DCL
一种可对数据访问权进行控制的指令.
DCL用来授予或回收数据库的某种特权, 并控制数据库操纵事务发生的时间及效果, 对数据库实行监视等.
grant, revoke
数据操纵语言DML
实现对数据库的基本造作, 对数据库中的对象和数据运行访问工作的语言.
主要功能是访问数据
insert, update, delete
数据查询语言DQL
负责进行数据查询而不会对数据本身进行修改的语句.
select, 常与from, where, group by, having, order by等子句联合使用
SQL数据类型
在创建表的列时, 必须指定数据类型.
MYSQL提供了这些:
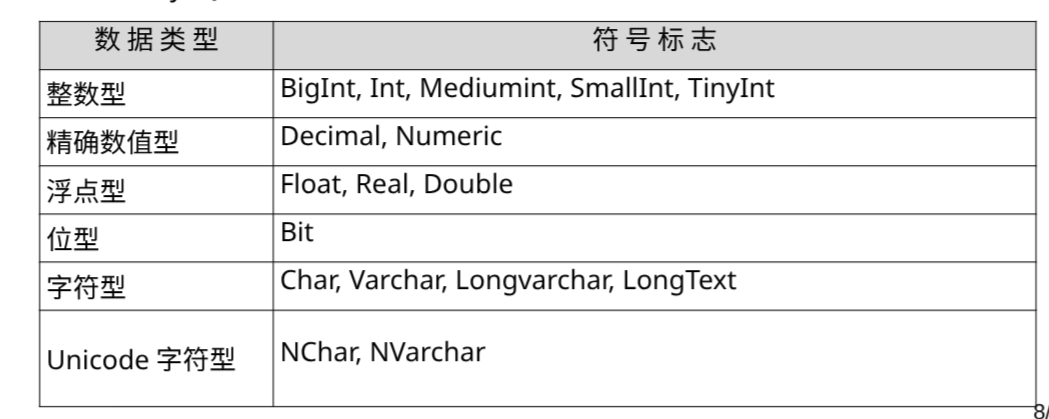
需要关注:
- 精度: 存储的十进制数据的总位数
- 小数位数: 小数点右边可以有多数字位数的最大值.
eg: 3560.697的精度是7, 小数位数是3
- 长度: 存储数据所使用的字节数
前两个针对数值型数据
整数型
- BIGINT: 大整数, -2^63 到 2^63-1, 精度为19, 小数位数为0, 长度为8字节
- INTERGER(INT): 整数, -2^31 到 2^31-1, 精度为10, 小数位数为0, 长度为4字节
- MEDIUMINT: 中等整数, -2^23 到 2^23-1, 精度为7, 小数位数为0, 长度为3字节
- SMALLINT: 小整数, -2^15 到 2^15-1, 精度为5, 小数位数为0, 长度为2字节
- TINYINT: 微小整数, -2^7 到 2^7-1, 精度为3, 小数位数为0, 长度为1字节
精确数值型
- DECIMAL(M,D): 定点数, -10^M + 10^-D 到 10^M - 10^-D, 精度为M, 小数位数为D, 长度为可变
- NUMERIC(M,D): 数值, -10^M + 10^-D 到 10^M - 10^-D, 精度为M, 小数位数为D, 长度为可变
两者功能上完全等价, 区别在于decimal不能用于带有identity属性的列
浮点型
- FLOAT(M,D): 单精度浮点数, -3.402823466E+38 到 -1.175494351E-38, 0, 1.175494351E-38 到 3.402823466E+38, 精度为M, 小数位数为D, 长度为4字节
- DOUBLE(M,D): 双精度浮点数, -1.7976931348623157E+308 到 -2.2250738585072014E-308, 0, 2.2250738585072014E-308 到 1.7976931348623157E+308, 精度为M, 小数位数为D, 长度为8字节
位型
- BIT(M): 位字段类型, 0 到 2^M -1, 精度为M, 小数位数为0, 长度为可变
M的取值范围是1到64, 默认值为1
字符型
- CHAR(M): 定长字符串
M的取值范围是1到255, 默认值为1
存储的数据一定是M个字符, 不足M个字符时, 用空格补齐
- VARCHAR(M): 变长字符串, 0 到 65535字符
M的取值范围是0到65535. 表示字符串的最大长度
文本型
- TINYTEXT: 极小文本, 最大长度
字节 - TEXT: 文本, 最大长度
字节 - MEDIUMTEXT: 中等文本, 最大长度
字节 - LONGTEXT: 大文本, 最大长度
字节
BINARY和VARBINARY型
- BINARY(M): 定长二进制字符串
M的取值范围是1到255, 默认值为1 存储的数据一定是M个字节, 不足M个字节时, 用0x00补齐
- VARBINARY(M): 变长二进制字符串, 0 到 65535字节
M的取值范围是0到65535. 表示字符串的最大长度 存储长度为实际输入数据长度+4字节
BLOB类型
- TINYBLOB: 极小二进制大对象, 最大长度
字节 - BLOB: 二进制大对象, 最大长度
字节 - MEDIUMBLOB: 中等二进制大对象, 最大长度
字节 - LONGBLOB: 大二进制大对象, 最大长度
字节
日期时间类型
- DATE: 日期, '1000-01-01' 到 '9999-12-31', 长度为3字节
- DATETIME: 日期和时间, '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59', 长度为8字节
- TIMESTAMP: 时间戳, '1970-01-01 00:00:01' UTC 到 '2038-01-19 03:14:07' UTC, 长度为4字节
- TIME: 时间, '-838:59:59' 到 '838:59:59', 长度为3字节
- YEAR: 年, 1901 到 2155, 长度为1字节
ENUM和SET类型
- ENUM: 枚举类型, 1 到 65535个不同的值, 长度为1或2字节
ENUM类型的列可以有一个空值
- SET: 集合类型, 1 到 64个不同的值, 长度为1到8字节
SET类型的列可以有一个空值
数据库操作
创建数据库
CREATE DATABASE [IF NOT EXISTS] 数据库名;MySQL中不区分大小写
使用数据库
USE 数据库名;删除数据库
DROP DATABASE [IF EXISTS] 数据库名;查看数据库
SHOW DATABASES;SQL模式定义
SQL模式表示为基本表, 视图等的集合.
SQL模式定义语句基本组成为:
模式名称 + 模式所有者 + 模式中包含的每个元素其中, 模式中包含元素为表, 视图, 索引等, 这些在模式定义中为可选项.
SQL模式由CREATE语句定义.
CREATE SCHEMA 模式名称
[ AUTHORIZATION 模式所有者 ]
[ CREATE TABLE 语句 ]
[ CREATE VIEW 语句 ]
[ CREATE INDEX 语句 ]
...
;删除SQL模式
DROP SCHEMA 模式名称 [ CASCADE | RESTRICT ];- CASCADE: 级联删除模式中的所有对象
- RESTRICT: 如果模式中包含对象, 则不允许删除模式
SQL数据表操作
创建表
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] 表名称
(
列名称 数据类型 [列约束],
...
[表约束]
);- TEMPORARY: 创建临时表, 临时表在会话结束时自动删除
- IF NOT EXISTS: 如果表不存在, 则创建表; 否则不执行
- 列约束: 定义列的约束条件, 如主键, 唯一性, 非空等
NULL/NOT NULL, 默认NULL
DEFAULT default_value: 设置默认值
AUTO_INCREMENT: 自动递增
UNIQUE: 唯一约束
PRIMARY KEY: 主键约束
COMMENT 'string': 添加注释
- 表约束: 定义表的约束条件, 如主键, 外键
修改表
- 添加属性列
ALTER TABLE 表名称
ADD 列名称 数据类型 [列约束];- 删除属性列
ALTER TABLE 表名称
DROP COLUMN 列名称 [CASCADE | RESTRICT];CASCADE: 级联删除与该列相关的约束 RESTRICT: 如果该列有相关约束, 则不允许删除
- 修改属性列
ALTER TABLE 表名称
MODIFY COLUMN 列名称 新数据类型 [列约束];- 补充定义主键
ALTER TABLE 表名称
ADD PRIMARY KEY (列名称);

- 删除表
DROP TABLE [IF EXISTS] 表名称 [CASCADE | RESTRICT];插入表数据
INSERT INTO 表名称 (列1, 列2, ...)
VALUES (值1, 值2, ...);- VALUES: 指定要插入的值, 值的顺序必须与列的顺序一致
更新表数据
UPDATE 表名称
SET 列1 = 值1, 列2 = 值2, ...
[WHERE 条件];- WHERE: 指定更新条件, 如果省略, 则更新所有行
- SET: 指定要更新的列及其新值
删除表数据
DELETE FROM 表名称
[WHERE 条件];SQL查询操作
SQL数据查询语法
SELECT [DISTINCT | ALL] 列1, 列2, ...
FROM 表名称
[WHERE 条件]
[GROUP BY 列1, 列2, ... [ASC|DESC]]
[HAVING 条件]
[ORDER BY 列1, 列2, ... [ASC|DESC]];
[LIMIT 数量 OFFSET 偏移量];FROM
FROM <table-name>
FROM <database-name>.<table-name>
FROM <table-name> <alias>
WHERE
WHERE <condition>
DISTINCT
确保不重复. 在指定的列里, NULL会被当作相同的值
附加基本运算
- 更名运算
SELECT 列名称 AS 别名
...
;- 字符串运算(查询通配符)
LIKE: 模糊查询
百分号%: 表示任意数量的字符(包括零个字符)
下划线_: 表示单个任意字符
SELECT 列名称
FROM 表名称
WHERE 列名称 LIKE '模式';
-- WHERE 列名称 LIKE 'a%'; -- 以a开头的所有值- 其它运算符
IN, NOT IN
LIKE
IS NULL, IS NOT NULL
<, >=, ...
AND, OR, NOT
ORDER BY
ORDER BY `<column-name>` [ASC|DESC], ...- ASC: 升序排列, 默认值
- DESC: 降序排列
LIMIT
LIMIT 数量;
LIMIT 偏移量 数量;- 数量: 指定返回的记录数
- 偏移量: 跳过的记录数
集合运算
交集INTERSECT
(SELECT 列1, 列2, ...
FROM A
WHERE 条件1)
INTERSECT
(SELECT 列3, 列4, ...
FROM A
WHERE 条件2);<=>
SELECT 列1, 列2, ...
FROM A
WHERE 条件1 AND 条件2;并集UNION
(SELECT 列1, 列2, ...)
UNION
(SELECT 列3, 列4, ...);<=>
SELECT 列1, 列2, ...
FROM A
WHERE 条件1
OR 条件2;差集EXCEPT
SELECT id FROM A
EXCEPT
SELECT id FROM B;<=>
SELECT id FROM A AS a
WHERE NOT EXISTS (
SELECT 1
FROM B AS b
WHERE b.id = a.id
);SELECT a.id
FROM A AS a
LEFT JOIN B AS b ON a.id = b.id
WHERE b.id IS NULL;可以使用NOT EXISTS或者LEFT JOIN来实现差集操作
eg:
SELECT 列1, 列2, ...
FROM A AS a
WHERE NOT EXISTS (
SELECT 1
FROM A AS b
WHERE b.列3 = a.列1 AND b.列4 = a.列2
);聚集函数
COUNT
计算行数
SELECT COUNT(列名称或者*)
FROM 表名称
[WHERE 条件];-- 计算student表中的总行数
SELECT COUNT(*) FROM student;
-- 计算student表中age列的非NULL值的数量
SELECT COUNT(age) FROM student;SUM
计算数值列的总和
SELECT SUM(列名称)
FROM 表名称
[WHERE 条件];AVG
计算数值列的平均值
SELECT AVG(列名称)
FROM 表名称
[WHERE 条件];MAX
计算列中的最大值
SELECT MAX(列名称)
FROM 表名称
[WHERE 条件];MIN
计算列中的最小值
SELECT MIN(列名称)
FROM 表名称
[WHERE 条件];GROUP BY
用于将结果集按一个或多个列进行分组, 通常与聚集函数一起使用
SELECT 列1, 列2, 聚集函数(列3)
FROM 表名称
[WHERE 条件]
GROUP BY 列1, 列2;有GROUP BY时, 聚集函数会分组计算
GROUP_CONCAT
将分组后的多个值连接成一个字符串
WITH ROLLUP
用于生成分组汇总行
SELECT 列1, 列2, 聚集函数(列3)
FROM 表名称
[WHERE 条件]
GROUP BY 列1, 列2 WITH ROLLUP;HAVING
用于对分组后的结果进行过滤, 通常与GROUP BY一起使用
SELECT 列1, 列2, 聚集函数(列3)
FROM 表名称
[WHERE 条件]
GROUP BY 列1, 列2
HAVING 聚集函数(列3) 条件;嵌套子查询
SELECT 列1, 列2, ...
FROM 表名称
WHERE 列3 IN (
SELECT 列4
FROM 另一个表名称
WHERE 条件
);