同步原语
同步带来的问题
多核场景
当单核性能提升遇到瓶颈时, 可以通过增加 CPU 核数来提升性能.
但是这样会产生一个问题, 假如多个线程都同时修改某个变量时, 就可能出现冲突.
并且资源就这么多, 开再多线程也会有线程是闲置的.
package main
import (
"fmt"
"sync"
)
func func1() {
balance := 0
group := sync.WaitGroup{}
for range 3 {
go func () {
defer group.Done()
group.Add(1)
for range 20000 {
balance++
}
fmt.Println(balance)
} ()
}
group.Wait()
}
func main() {
func1()
}可以试试这份代码, 没意外的话大概率不会出现理想的 20000, 40000, 60000. 反正我一次都没打印出来.
这是因为 balance++这个操作不是原子性的, 它可以拆成
temp := balance
temp = temp + 1
balance = temp假如有两个线程同时执行了 balance = balance + 1,
分别在两个 CPU 执行: 由于获取的 balance 都是同一个值, 最后也只加一个 1, 但是原本是加 2 的.
在同一个 CPU 执行: 假如
temp := balance后, 切换到另一个线程了, 这样两个线程的 temp 都是同一个值, 跟刚刚一样了. 也是只+1.
理想的情况是, 一个线程完成这一个 balance++的整个操作后, 另一个线程才继续 balance++
生产者消费者模型
来想一个比较简单的场景, 单一生产者和单一消费者. 大概就是生产者负责生产任务, 消费者会来取任务然后执行.
需要一个数组来存任务, 就叫任务队列吧. 需要维护两个变量, 一个表示还有多少个空位, 给生产者用; 一个表示多少个任务在里面, 给消费者用.
不管是生产任务, 还是获取任务, 都是从数组第一个元素开始, 到头了就回到第一个元素, 相当于一个循环队列, 因此双方都需要维护一个变量, 表示下一个索引.
在单生产者和单消费者的情况很简单, 但是如果是多生产者的话, 就会遇到一个问题:
跟 balance++一样, 读取下一个位置后还需要存放数据, 假如两个线程同时读取了下一个位置, 那么就会在同一个地方存放数据, 造成数据覆盖.
同样的, 如果另一个线程能等第一个线程做完再做就好了.
临界区问题
为了确保一个线程在使用某些共享资源时, 其它线程不能访问这些资源, 提出一个临界区的概念, 只允许线程在临界区使用共享资源.
线程想进入临界区, 必须先申请进入临界区, 得到同意后才能进入临界区. 退出时, 需要显示地标示出来自己退出了临界区.
互斥访问 同一时刻, 最多只有一个线程进入临界区
空闲让进 没有线程在临界区时, 必须选一个线程允许其进入临界区
有限等待 当线程申请进入临界区时, 必须在有限时间内获取许可
在单核下, 线程是按时间片调度的, 只要关掉中断, 就能保证临界区只有一个程序了.
但是多核情况下, 一个核是不能阻塞其它核的运行的.
互斥锁
互斥锁是一种比较大的概念, 至少在书上是这样的. 自旋锁, 排号自旋锁等都是互斥锁的一种实现.
皮特森算法
这是一种支持两个线程共享资源访问的算法, 谦让的算法.
当准备进入临界区时, 让对方进.
func thread0() {
flag[0] = true // 表示自己要申请进入临界区了
turn = 1 // 先让对方进吧
for flag[1] && turn == 1 {} // 等对方退出临界区
// 临界区
flag[0] = false // 退出
}
func thread1() {
flag[1] = true
turn = 0
for flag[0] && turn == 0 {}
// ...
flag[1] = false
}这样的话, 无论操作顺序如何, 最后 turn 要么 0 要么 1, 只有一个线程可以进入临界区.
但是这样也存在一个问题. 那就是要求两个线程的内部有序执行. 也就是说, 不能先等对面进入临界区, 再让 turn=1. 不能内部先读 turn 再写 turn.
这个只适用于两个线程, 后来有人扩展了可以用于任意多线程.
现代 CPU 为了高效, 有乱序执行机制, 因此皮特森算法会失效.
原子操作
软硬结合的方法.
原子操作就是不可被打断的一个或一系列操作.
之前的 balance++就是因为它被打断了, 才发生错误.
常见的原子操作
- 比较与置换 Compare And Swap, CAS
等价于
int CAS(int *addr, int excepted, int new_value) {
int temp = addr;
if (*addr == excepted) {
*addr = new_value;
}
return temp;
}只是说结果上等价, 不是说过程上等价. 如果直接编译的话, 上面这个函数会变成多条汇编指令, 原子操作只有一条汇编指令.
在有些实现中, 如果置换成功则返回 true, 否则返回 false.
- 拿取并累加 Fetch And Add, FAA
等价于
int FAA(int *addr, int add_value) {
int temp = *addr;
*addr = temp + add_value;
return temp;
}intel 锁总线实现原子操作
原子操作依赖硬件.
intel 的 CPU 有一个锁总线, 对任意地址的修改都要经过总线. 当一个 CPU 要进行原子操作时, 会在锁总线发送一个地址, 然后锁定锁总线. 完成后解锁.
如果锁定期间有 CPU 想修改这个地址, 就会遇到锁而发送地址失败, 这个 CPU 就不能进行修改了.
ARM 使用 LL/SC 实现原子操作
ARM 的 CPU 会在读的时候监视这个地址, 修改的时候看地址是否被其他人改过, 如果没人改就成功了, 否则回到读指令重试.
互斥锁抽象
这个互斥锁需要有解锁和上锁接口, 上锁就相当于请求进入临界区, 解锁就是表示退出临界区.
自旋锁
void lock_int() {
*lock = 0;
}
void lock() {
while (atomic_CAS(lock, 0, 1) != 0);
}
void unlock() {
*lock = 0;
}这个就是自旋锁的大概实现. 每个线程调用 lock 时, 会使用原子操作试图把 lock 改 1, 如果改成功了, 那么就进入了临界区; 如果没成功, 就继续改.
只会有一个线程成功改 1, 如果 lock 是 1 的话, 那肯定置换不成功了.
这样可以保证互斥访问和空闲让进, 效率高, 响应快.
但是不能保证有限等待, 批准进入临界区也很随意, 不公平. 运气差的线程可能永远不成功.
排号自旋锁
struct lock {
int owner;
int next;
}
void lock_init(struct lock *lock) {
lock->owner = 0;
lock->next = 0;
}
void lock(struct lock *lock) {
int my_ticket = atomic_FAA(&lock->next, 1);
while (lock->owner != my_ticket);
}
void unlock(struct lock *lock) {
lock->owner++;
}当申请进入临界区时, 线程会被分配一个编号(线程看不到这个编号), 轮到自己的时候就进入临界区了.
owner 就是现在在使用的线程编号, 当这个线程使用完后, owner++, 让下一个线程使用.
这样子三个愿望都满足了.
不过不管是普通的自旋锁, 还是排号自旋锁都有一个问题, 那就是需要忙等. CPU 需要一直尝试改 lock 的值, 一部分 CPU 时间都用在这里了.
要是可以让线程进入阻塞态就好了, 等时机成熟操作系统再把它唤醒进入就绪态. 这样可以节约 CPU 资源.
条件变量
类似事件的发布订阅, 要求实现两个接口:
void cond_wait();
void cond_signal();wait 表示自己在等待某个事件, signal 表示某个事件发布了, wait 的线程可以被唤醒了. 当然要传参了, 参数就是事件.
这个 signal 决定不可能是 wait 的线程调用的, 因为 wait 的线程都在睡觉, 只有可能是其它线程调用.
struct cond {
struct thread *wait_list;
}
void cond_wait(struct cond *cond, struct lock *mutex) {
list_append(cond->wait_list, thread_self());
atomic_block_unlock(mutex); // 原子挂起并释放锁
lock(mutex); // 重新获取互斥锁
}
void cond_signal(struct cond *cond) {
if (!list_empty(cond->wait_list)) {
wakeup(list_remove(cond->wait_list));
}
}
void cond_broadcast(struct cond *cond) {
while (!list_empty(cond->wait_list)) {
wakeup(list_remove(cond->wait_list));
}
}当一个线程申请进入临界区时, 会进入阻塞态并释放锁; 当其它线程调用 cond_signal 时, 这个线程就会转为就绪态, 然后重新获取互斥锁了. wakeup 通过系统调用来唤醒线程.
互斥锁保证临界区只有一个线程访问, 条件变量避免被堵在外面的线程循环等待. 这两个东西解决的不是同一个东西, 条件变量需要配合互斥锁使用.
信号量
条件变量依旧存在不足, cond 的定义和条件声明是分离的, 在开发的时候我们还得记着哪个 cond 对应哪个条件, 很容易出错. 需要将条件和变量统一起来.
PV
P 检验, 代码中用 wait 表示
V 自增, 代码中用 signal 表示
void wait(int *S) {
while (*S <= 0);
*S = *S - 1;
}
void signal(int *S) {
*S = *S + 1;
}效果上是这样的, 不过里面可以看作是原子操作. 下面是其中一种实现.
struct sem {
// 为正时, 表示剩余资源数量;
// 为负时, 绝对值表示正在等待的线程数量
int value;
// 应当唤醒的资源数量
int wakeup;
struct lock sem_lock;
struct cond sem_cond;
}
void wait(struct sem *S) {
lock(&S->sem_lock);
S->value--;
if (S->value < 0) { // 没有资源可以用了, 让线程先等着吧
do {
cond_wait(&S->sem_cond, &S->sem_lock);
} while (S->wakeup == 0);
S->wakeup--;
}
unlock(&S->sem_lock);
}
void signal(struct sem *S) {
lock(&S->sem_lock);
S->value++;
if (S->value <= 0) { // 如果有之前有线程在等的话
S->wakeup++;
cond_signal(&S->sem_cond); // 就通知一下线程
}
unlock(&S->sem_lock);
}读写锁
互斥锁只是为了防止线程对共享资源的修改, 但是读取不应该被阻止, 除非有人在写.
因此需要有读写锁, 可以提高性能.
读写锁允许读者之间并行, 读者与写者之间互斥, 写者与写着之间也互斥.
不过读写锁只在读多写少的情况下性能提升才明显.
读写锁更偏向与写者.
假设现在有一个读者在使用临界区,
如果来了一个读者, 那么它进入临界区.
如果来了一个写者, 那么它等待. 如果之后又来了读者, 后序读者也等着, 等写者写完.
读写锁也可以偏向读者, 看实现.
::: code-groups
struct rwlock {
int reader_cnt;
struct lock reader_lock;
struct lock writer_lock;
}
void lock_reader(struct rwlock *lock) {
lock(&lock->reader_lock);
lock->reader_cnt++;
if(lock->reader_cnt == 1) {
// 第一个读者
lock(&lock->writer_lock);
}
unlock(&lock->reader_lock);
}
void lock_writer(struct rwlock *lock) {
lock(&lock->writer_lock);
}
void unlock_writer(struct rwlock *lock) {
unlock(&lock->writer_lock);
}struct rwlock {
int reader_cnt;
bool has_writer;
struct lock lock;
struct cond reader_cond;
struct cond writer_cond;
};
void lock_reader(struct rwlock *rwlock) {
lock(&rwlock->lock);
while(rwlock->has_writer == TRUE) {
cond_wait(&rwlock->writer_cond, &rwlock->lock);
}
rwlock->reader_cnt++;
unlock(&rwlock->lock);
}
void unlock_reader(struct rwlock *rwlock) {
lock(&rwlock->lock);
rwlock->reader_cnt--;
if(rwlock->reader_cnt == 0) {
cond_signal(&rwlock->reader_cond);
}
unlock(&rwlock->lock);
}:::
同步原语产生的问题
死锁
特定顺序获取资源就可能不死锁, 不死锁的调用顺序就是安全序列.
银行家算法
所有线程获取资源都需要管理员同意
管理员 预演 会不会造成死锁
如果会造成死锁, 阻塞线程, 下次再给资源
如果不会造成, 给线程资源
大概就是管理员维护一个数组, 这个数组里的每个元素需要有自己对某资源的最大需求量, 已分配资源量和还需要的资源量. 管理员自己还会维护全局可利用资源量.
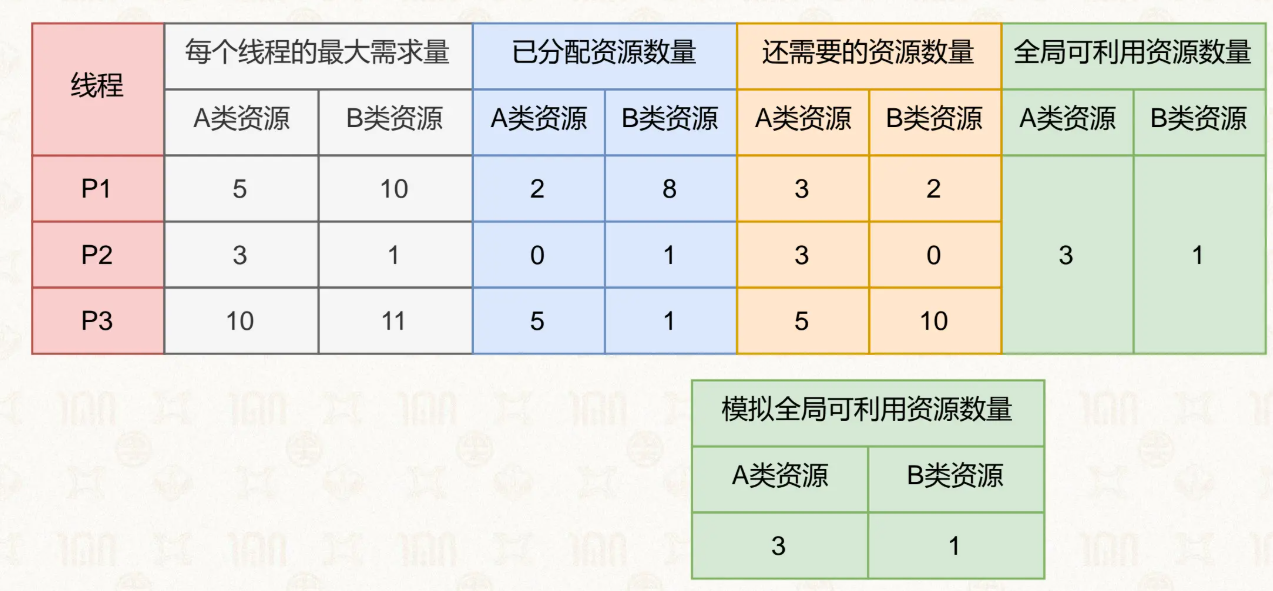
构建出这样一个数组
找到可以被执行的线程
模拟执行, 然后释放所有资源, 回到2
遍历所有线程, 检查是否都可以被执行
这样之后, 就可以得到一个安全序列. 只有按照安全序列调度线程就不会出现死锁了.
银行家算法有效的前提是, 这些资源的需求量都是静态的.
活锁
不允许持有并等待会产生活锁. 大概是这种情况
while (1) {
if (trylock(A) == SUCC) {
if (trylock(B) == SUCC) {
// ...临界区
unlock(B);
unlock(A);
} else {
unlock(A);
}
}
}可能会出现A拿到了, B拿不到, 然后释放A. 继续拿A拿B. 运气很差可能会出现如此往复, 不过一般运气不会一直这么差.
活锁大概率可以自行消除.